How to stabilize your runs in MARL
In my previous post, I introduced an environment for studying emergent cooperation in multi-agent systems. While the basic mechanics were functional, the training runs where severely unstable. This post documents the solutions to this issue.
Characterizing the instability
The instability manifested across two dimensions. First, runs with identical hyperparameters produced wildly divergent outcomes:
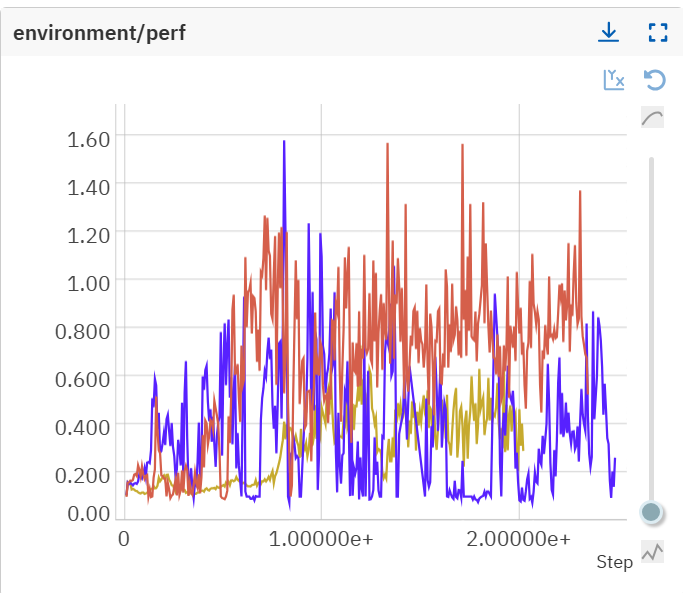
Second, hyperparameter sweep revealed training collapse (note: perf is normalized version of score, however, in those early experiments, perf could go above 1 due to a bug in my environment, which I fixed later):
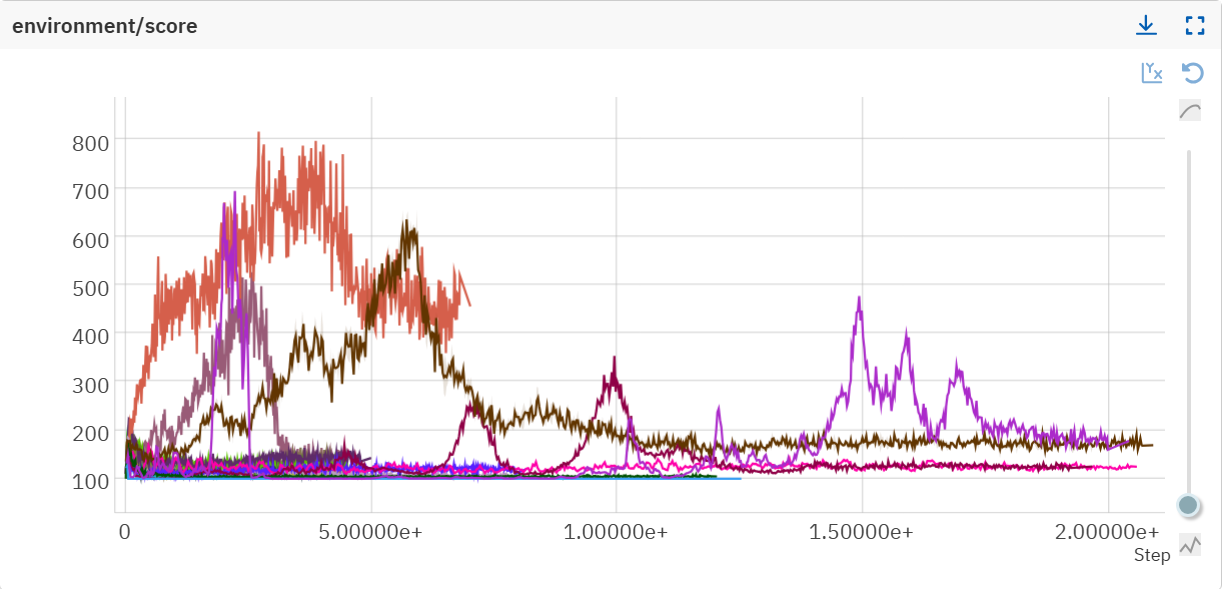
This level of variance made it impossible to distinguish genuine algorithmic improvements from random noise. Before adding environmental complexity, I needed to isolate and fix these sources of instability.
Solutions
Here is the list of things which helped:
- Rigorous logging validation
- Isolate non-determinism
- Randomize initial state distribution
- Sweep your rewards
Solution 1: Rigorous logging validation
Because you won’t be rendering thousands of experiments at different checkpoints, your logs are everything. If your log is bugged, or shows some metric which isn’t actually what you care about, you’re doomed to lose hours of work. So make sure these work.
I learned this the hard way. My initial logging measured agent survival time, but the implementation had subtle bugs in how it aggregated data across vectorized environments. Some edge cases (like agents surviving the entire episode) were never logged. Others were double-counted due to incorrect episode boundary handling.
Solution 2: Isolate non-determinism
Multi-agent RL environments accumulate sources of randomness: policy stochasticity, environment dynamics, GPU operations, floating-point arithmetic. Left unchecked, these make debugging nearly impossible.
The problem: you might have subtle bugs that only surface after hundreds of millions of steps. At that point, attributing failure to the algorithm versus the environment becomes guesswork.
My approach: aggressively seed everything and start simple. One environment, CPU execution, deterministic policy. Verify that trajectories are reproducible. Only then scale up. This establishes a ground truth you can return to when things break.
Solution 3: Randomize initial state distribution
This one is pretty straightforward but this really help agent see more diverse trajectories early on and learn a more stable policy.
Solution 4: Sweep your rewards
At first I was against changing the reward structure. I really wanted the agents to solve the task with minimal signal (death = -1). It turns out bad rewards can really screw your runs and there is nothing wrong with sweeping the rewards as long as you keep your main metric fixed.
Here is an example of a stable reward configuration that consistently solves the environment in under 25M steps:
| Reward Component | Description | Value |
|---|---|---|
| held_food_reward_scale | Inventory holding reward | 0.26 |
| hp_reward_scale | Current health reward (per timestep) | 0.07 |
| reward_collect | Food collection reward | 1.0 |
| reward_death_scale | Normalized survival time reward | 0.14 |
| reward_eat | Consumption reward | 0.63 |
| reward_steal | Stealing penalty | -0.46 |
| timestep_reward | Living penalty (per timestep) | -0.001 |
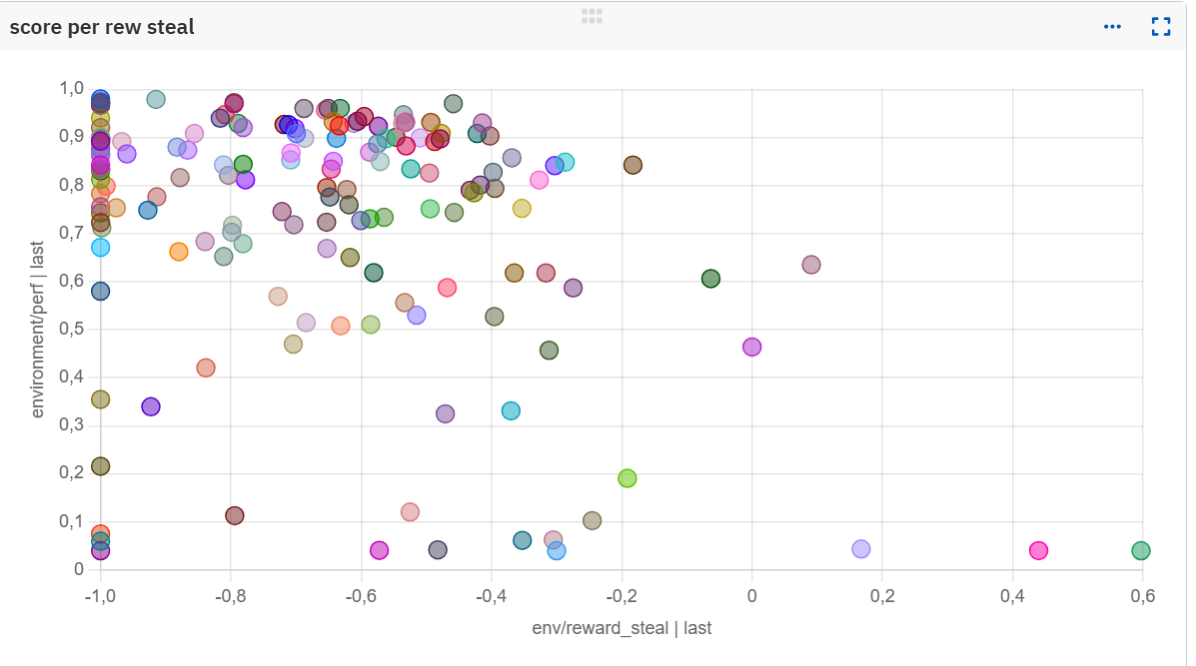
Reward-performance correlation
Analyzing reward-performance correlations across the sweep revealed clear patterns. Each dot is a single experiment with different rewards parameters. Discouraging theft seems essential:
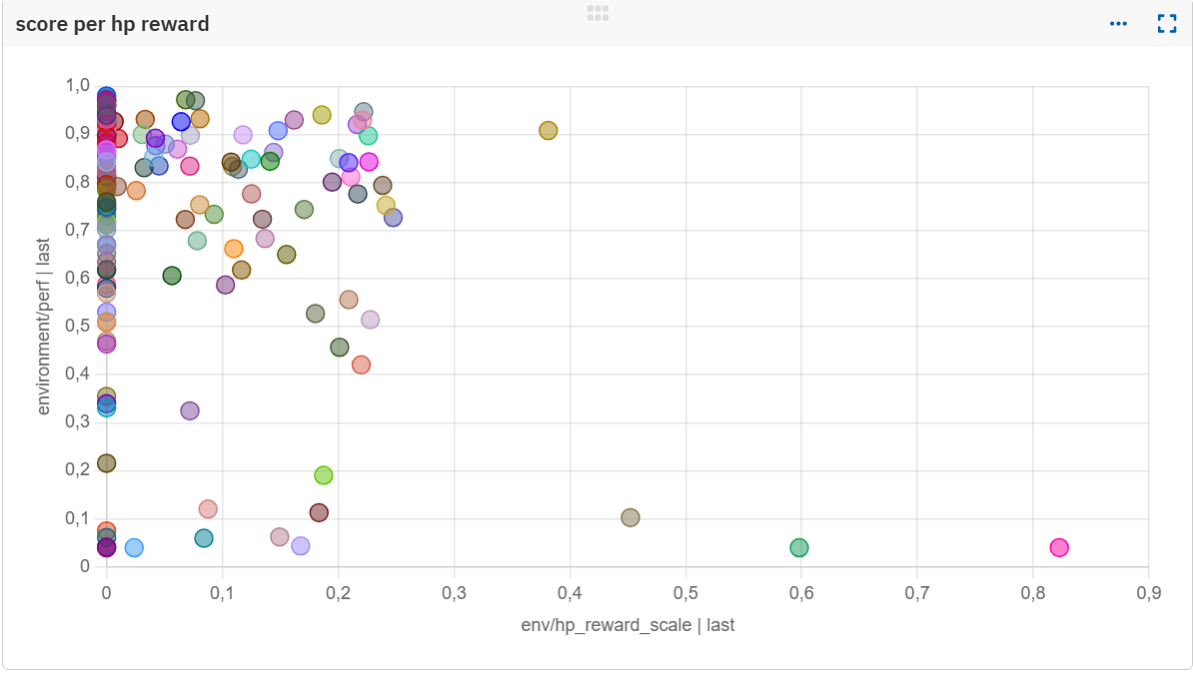
Interestingly, dense HP-based rewards provided minimal benefit, possibly due to it being too noisy:
Maybe more obvious, rewarding collection and consumption behaviors proved essential:
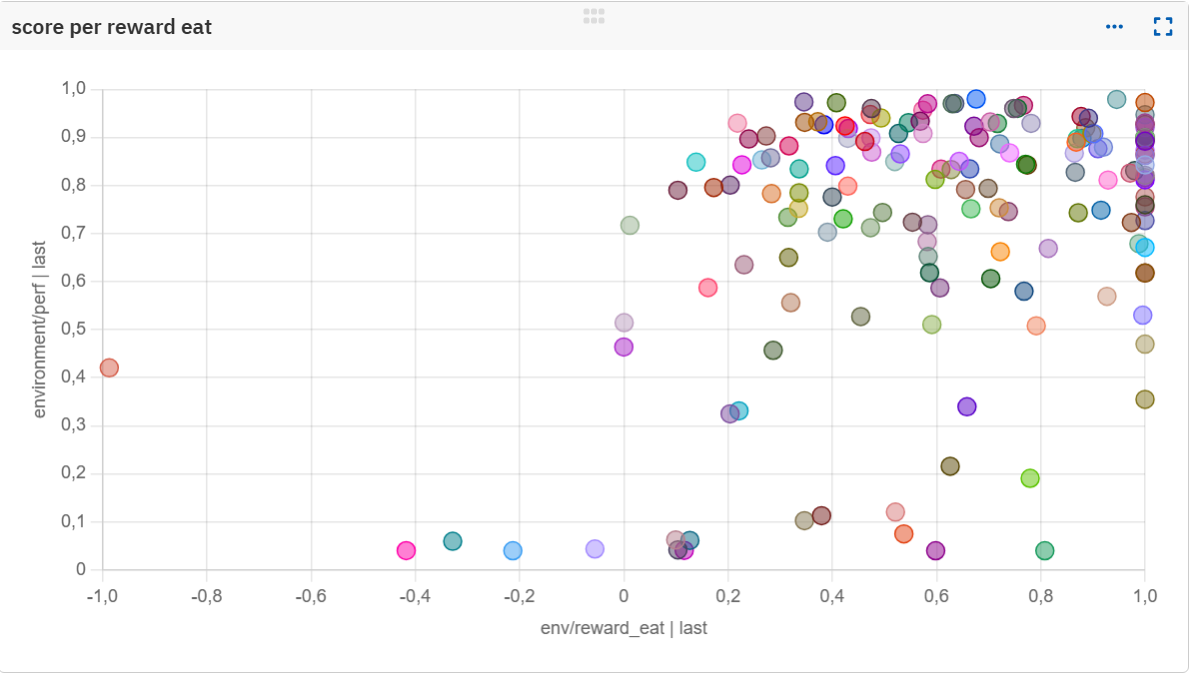
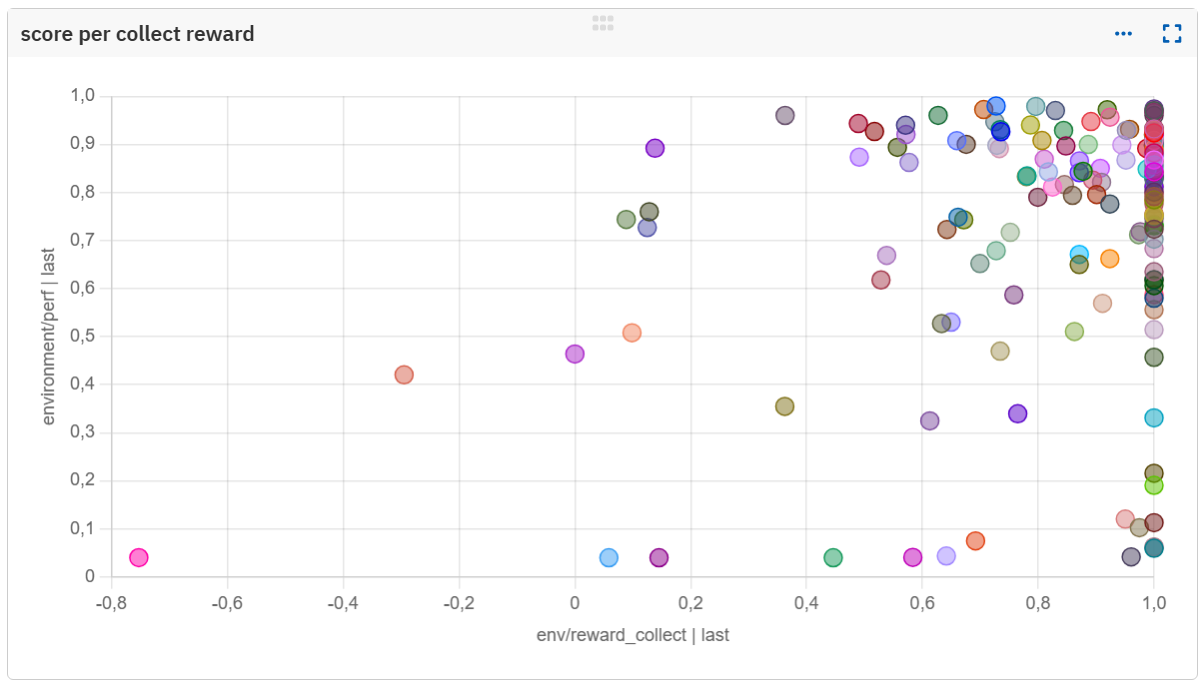
Results: Establishing a stable baseline
The original training curves demonstrated severe instability:
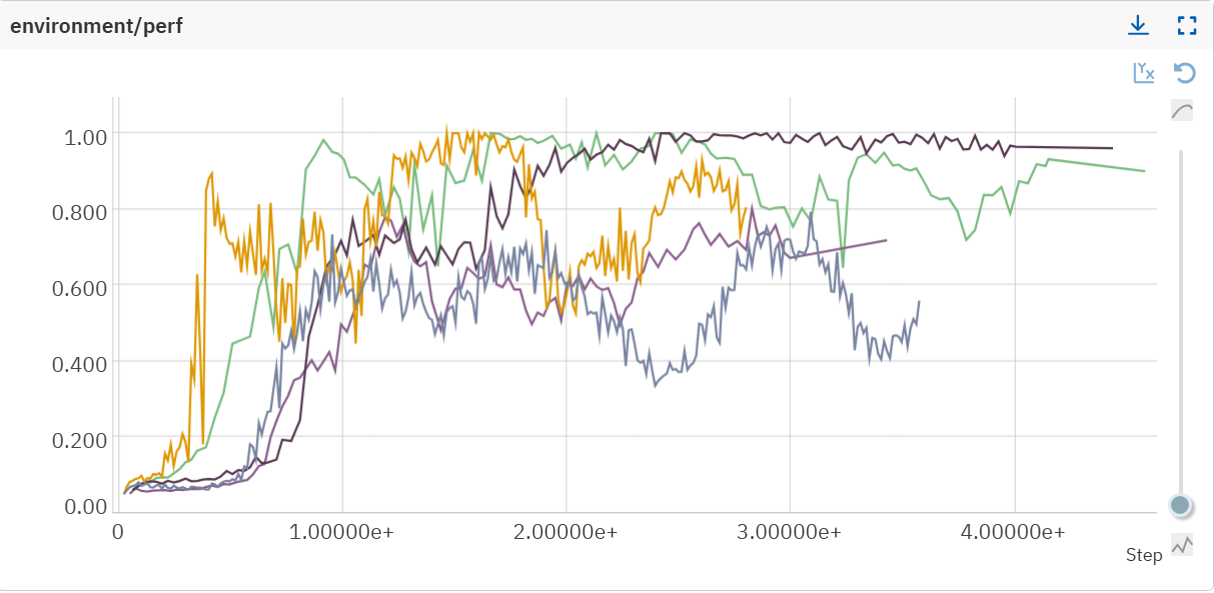
Now, agents consistently reach high performance without sudden collapse, across multiple independent runs:
Demonstration and next steps
The video below shows a solved rollout. Agents spawn in the house region (grey tiles, bottom-left) and learn to survive by collecting & eating food:
Now that I get stable runs, I can move on and increase the environment complexity to make things even more interesting.