The simplest thing that makes diverse skills
I wanted to find the simplest possible setup that produces behavioral diversity in RL. Not a full skill discovery method, just the minimal thing that works, so I understand what actually drives diversity before building anything bigger.
The setup: a small gridworld, one agent, 5 skills. My toy notion of “diverse” is dead simple. Each skill should make the agent do something different. Skill 0 always goes up, skill 1 always goes down, and so on. Five skills, five actions, five distinct behaviors.
Ignore the red square in the image below, as it’s supposed to be the goal for the environment, but we’re overriding the task for our purposes.
Gridworld. The action space is {UP,DOWN,RIGHT,LEFT,NOOP}. Originally taken from pufferlib. Agent is Blue square. Ignore red square.
Skills, quickly
A skill is a latent \(z\) that conditions the policy. Instead of one policy \(\pi(a \mid s)\), you have \(\pi(a \mid s, z)\). Same network, different behavior depending on which \(z\) you feed it. I use 5 one-hot skills. Methods like DIAYN and METRA do this with a discriminator or a learned metric. I wanted something simpler.
The objective
I want the action distributions of different skills to be far apart. The natural measure is the total variation distance between the policy of one skill and the policy of the others:
\[\text{TV}(\pi(\cdot \mid s, z), \pi(\cdot \mid s, z')) = \frac{1}{2} \sum_a | \pi(a \mid s, z) - \pi(a \mid s, z') |\]For each skill, I average this over all the other skills. High TV means the skill behaves differently from the rest.
First try: TV as a reward. Doesn’t work.
My first idea was to use this TV as the reward and let PPO maximize it. It didn’t work. The skills collapsed, everything ended up doing the same thing.
Here is my hypothesis for why. The TV is a function of the whole action distribution, not of the action the agent actually sampled. But PPO optimizes rewards through the sampled action, via the advantage and the log-prob of that action. If the reward doesn’t depend on the action you took, PPO has no clean signal to push the policy. You’re trying to push a quantity through a channel that can’t carry it.
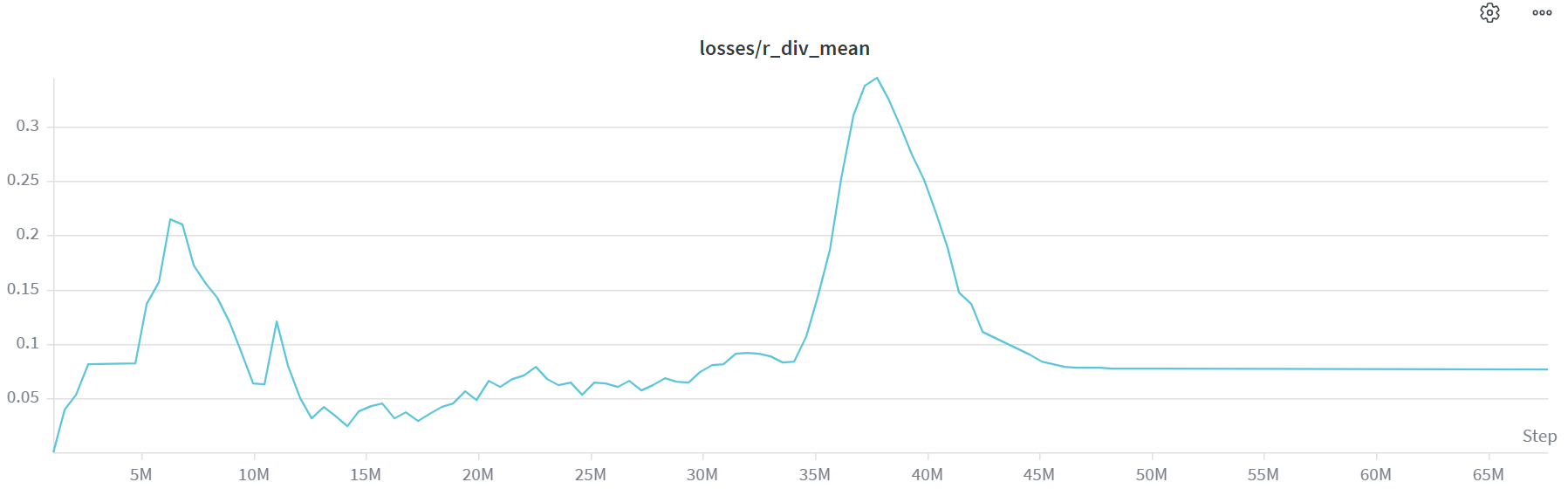
TV as an intrinsinc reward. Curve shows the average reward over every skill. Y axis is the average TV value, between 0 and 1. X axis is timesteps, in millions
What actually works: TV as a loss
The key thing I missed: the TV is differentiable with respect to the policy parameters. So I don’t need to route it through the reward at all. I can just put it directly in the loss and backprop through it.
\[\mathcal{L}_{\text{div}} = - \frac{1}{K-1} \sum_{z' \neq z} \text{TV}(\pi(\cdot \mid s, z), \pi(\cdot \mid s, z'))\]No reward, no advantage, no value function for this term. Just a differentiable loss, the same way an entropy bonus is a loss and not a reward.
This works. It converges fast and it’s stable, even when I changed hyperparameters. Each skill specializes on a different action.
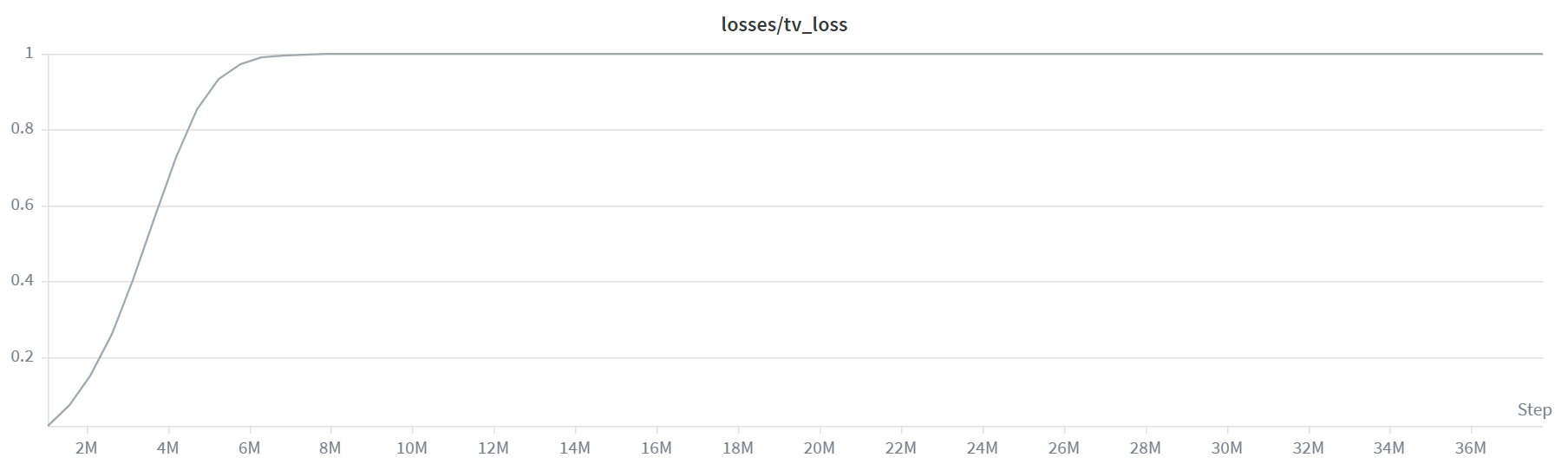
TV as an intrinsinc reward. Curve shows the average reward over every skill. Y axis is the average TV loss, between 0 and 1. X axis is timesteps, in millions
Skill 0 learned to go up
Skill 1 learned to go right
Takeaway
The lesson is about the channel, not the measure. A diversity term that depends on the policy distribution should be a loss, optimized by pathwise gradient, not a reward optimized by the score-function estimator. This is just an application of the distinction in Schulman et al. 2015 on gradient estimation.
Code is here: github.com/BoxingBytes.